
Beantextures Devlog 3 - It is SLOWER 💀
Background
It’s like 12 AM right now, lmao. I originally wanted to sleep earlier today and I regret not doing it. Instead, I just found a really, really sad truth about my THIRD iteration of Beantextures 💀 Idk how I’m gonna sleep now, lol.
The Biggest Twist
Okay, remember when I benchmarked a usual shader node setup with Beantextures v.2? That’s right ladies and gentlemen, that is NOT fair at all. There’s more to it.
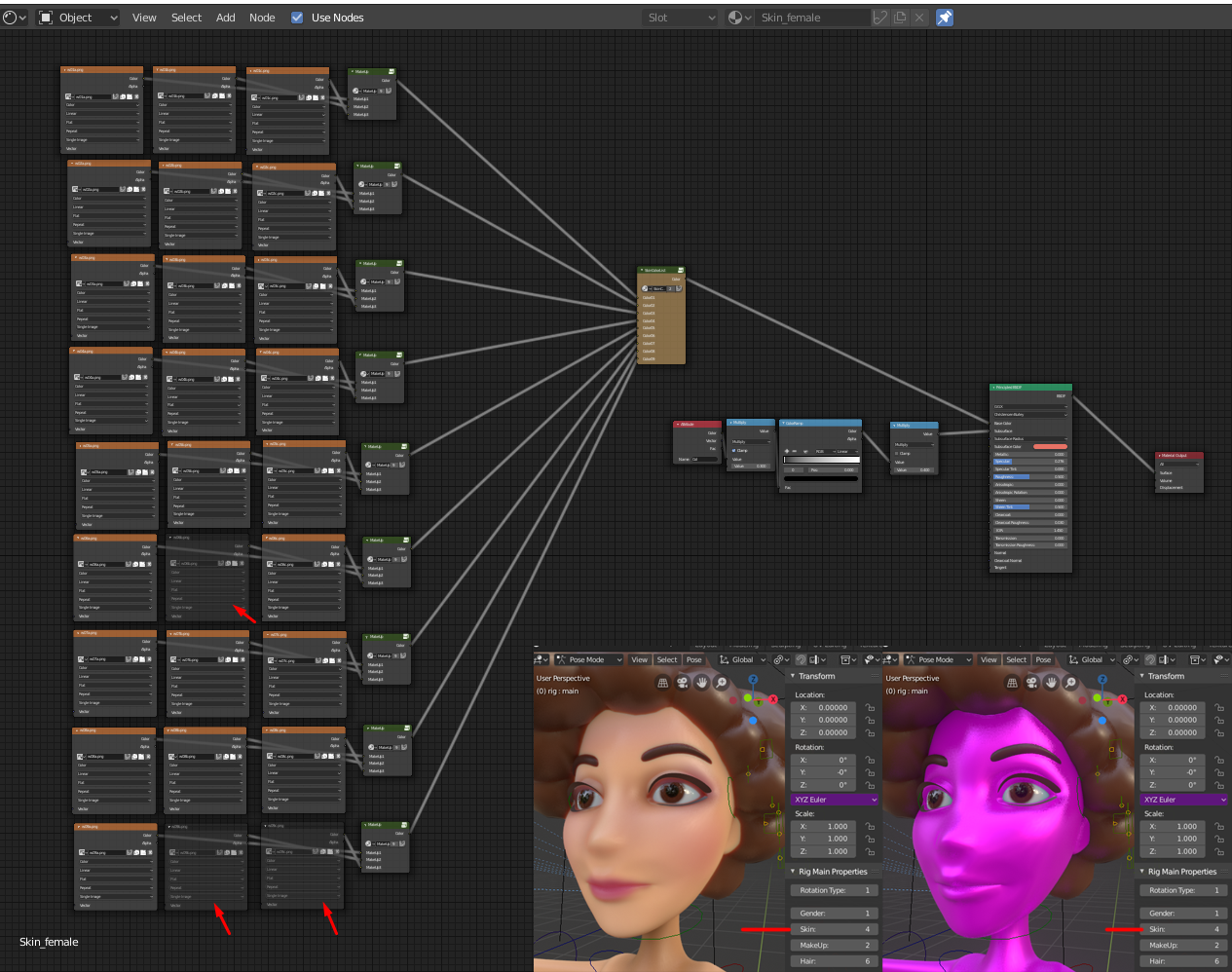
Alright but first, let me show you some progress I’ve done (almost nothing but ok). Well, I’ve added the actual node group generators. Very nice, very simple, lets Blender do all the work, ultra scalable, maintainable, future proof, just good. I like it.
So now, with the help of Beantextures, you can make a node group like this without fretting (but honestly, idk who needs a 2D facial expression rig with 49 images):

I made that node group setup for testing purposes. Now, just a while ago, instead of showing some actual image, the node group would crash and display a pink ‘texture not found’ as its color instead after it hits some 29-ish images. Kinda like this similar issue:
(Source: @mangojambo at Blender Stack Exchange)
I then found this other Blender Stack Exchange question, which suggested that EEVEE has a limitation that prevents you from having more than 24 images on one material:
I believe the limit for EEVEE is 24 textures per material. In cycles, you can get around the limitation by enabling “open shading language”, but I think in eevee, you’re stuck. In the end, it doesn’t matter what the “theoretical” limit is - If you hit a point where adding a new texture to the graph causes it all to turn pink, you just have to find some other way around it, such as using a texture atlas.
Also, I found these messages on the log xD:
ERROR (gpu.shader): GPU_material_compile Linking:
| Error: Too many fragment shader texture samplers
But after I relaunched Blender and opened the exact same file, it works. 49 images, compiled shader.
Well maybe time has gone by a lil; I can only find old threads where people talk about that issue, maybe it’s been resolved now and my issue is just because of some runtime bug.
The Sad Benchmark
That pink accident actually gave me a hunch—this could be slower than my previous Beantextures. And so I did some benchmarking, and the result is VERY WILD.
With Beantextures v2, it averages at around 32-ish % of CPU (color + alpha map, 49 images).
Now, you think that’s a lot? Nah, Beantextures v3 scored 65-ish %. That’s right, FUCKIN TWICE THE LOAD! Switching image on a node is faster than computing a full-fledged shader node, I guess.
Second Test
Okay, another test. This time with 7 images, color + alpha map. And the surprising thing is, both my v2 and v3 perform at almost the exact same performance—around 35 % of CPU. Oddly enough, v3 this time is heavier than with 49 images??
Why Though?
So totally, all those math nodes and mix nodes definitely add to the overall overhead. And I think that all of the images will need to be loaded to the memory during the compilation. On the other hand, my v2 Beantextures doesn’t require Blender to load everything straight away because it’s not needed directly. Only if we change the actual image used by the node, Blender will load that necessary image. This may make animating a little laggier initially, but ngl, it’s kinda good. Blender caches images, so the performance is gonna be pretty quick after all of the images are loaded.
The computational cost of v3 is totally wayy more exponential than my v2. I’m so dead honestly (also: I need sleep), I should do more benchmarks soon—will update here later.
nuuu
Lesson learned: BENCHMARK APPROACHES BEFORE YOU IMPLEMENT IT!! Idk why I didn’t do this, though. Oh wait it’s probably because early on, I was like, “Yeah let’s write how it may work. Nvm nahhhhhhh we write backend later I think. This is SEEEEERIOUSLY dead easy to implement”. But she really thought that it’s gon be performant 💀
Yep, I fell to the same hole again. But actually, no, this time I actually did implement it easily, it just had some performance issues.
Yk What,
I’m gonna beat the record of my most rewritten (shell, Python, C, Rust (kind of), prolly more to come, dunno why) software ever, whow. I’m gonna rewrite this again 💀✋
Why am I doing this to myself? I think that I really overthink (double overthinking!) about long-term project scalability lmao 😭
Or if not rewriting, I’m gonna just continue the older version which is honestly a BIG MESS. But eh, I should prolly ditch some of those edge cases that are never gonna happen irl, maybe let it be efficient (and messy, just like almost every other Blender add-ons) for once 💀
Or maybe even better idea: WE TRY DIFFERENT UV MAPS-BASED APPROACH! (with an image atlas which I personally don’t like though)